
I read many endless discussions about audio equipment: cables, lossless vs. lossy, compression algorithms, jitter, ultrasound, playback files from different places of hard disk, power conditioners, etc.
Probably, reason of the discussions is a small perceived sound difference, that is not obvious for everybody, or no difference.
It is the end of high-end?
Below I want to discuss: can we get sound improvement, obvious for almost everyone, in future audio equipment?

If you buy "AuI ConverteR PROduce-RD" (2023/12.x version) from 24 August 2023 to 24 October 2023, you will get free update to version 2024 (13.x) after its release.

All, I wrote below, is only my personal vision to perspectives of audio equipment from points of view developer and consumer of audio products.
Back to top
What is aim of audio hardware
When we discuss musical records of acoustic bands and orchestras, we want "naturalness" of playback audio.
Here "Natural sound" is sound similar to sound, that we can listen in concert hall.
In this meaning "naturalness" is degree of reconstruction correctness of concert hall sound in a listening room.
However, "naturalness" term is not so simple as it seemed.
There is no "natural" sound of a musical instrument. There is only "natural" sound of system [musical instrument + concert hall].
Back to top
What's happening now
In my opinion, modern hi-fi/hi-end audio devices are close to ideal in conception of low distortions.
The devices achieved low distortion-level in music transfer thru full system: from microphone to speakers in listening room.
Audio equipment distortions,
when music signal is transferred from microphone to listening room

Ideal system should have zero distortions: signal, that input to microphone, is radiated from speakers without any changes.
It is story about harmonic distortions, flatness or linearity of different kinds of responses.
Even cheap modern digital audio devices provide fair enough sound. Expensive devices sounds fine.
There are many discussions: we can hear difference between an audio units/settings/modding/processings or not? There are endless discussions.
I said above "close to ideal", because properly measured difference for human ears may be either enough small, or absent (including imaginary difference). Otherwise, there would are no discussions.
Below I want to discuss, that we can try do to get obvious sound difference for all classes of audio devices. Even for the best ones.
Back to top
Future issues
Let's watch the video for better understanding of subject discussion below:

It is very good video for illustration of lack of modern audio systems. Unfortunately, I don't know details of the experiment.
But my personal expressions by live music listening give me same feelings: live band sound better, than record; live sound have more "volume", "space", etc.
Look below to physics of the process.
1. Sound of live band.
At scene several omnidirectional audio sources (musical instruments) are placed. Acoustic waves are spread in all infinite number of directions around the sources.
Omnidirectional acoustic source spread acoustic waves (along rays) in all directions around

This infinite number of acoustic rays are bounced/adsorbed from/in surfaces of concert hall. Bounced rays re-bounced again.
Bouncing of acoustic rays, radiated by musical instruments, into concert hall
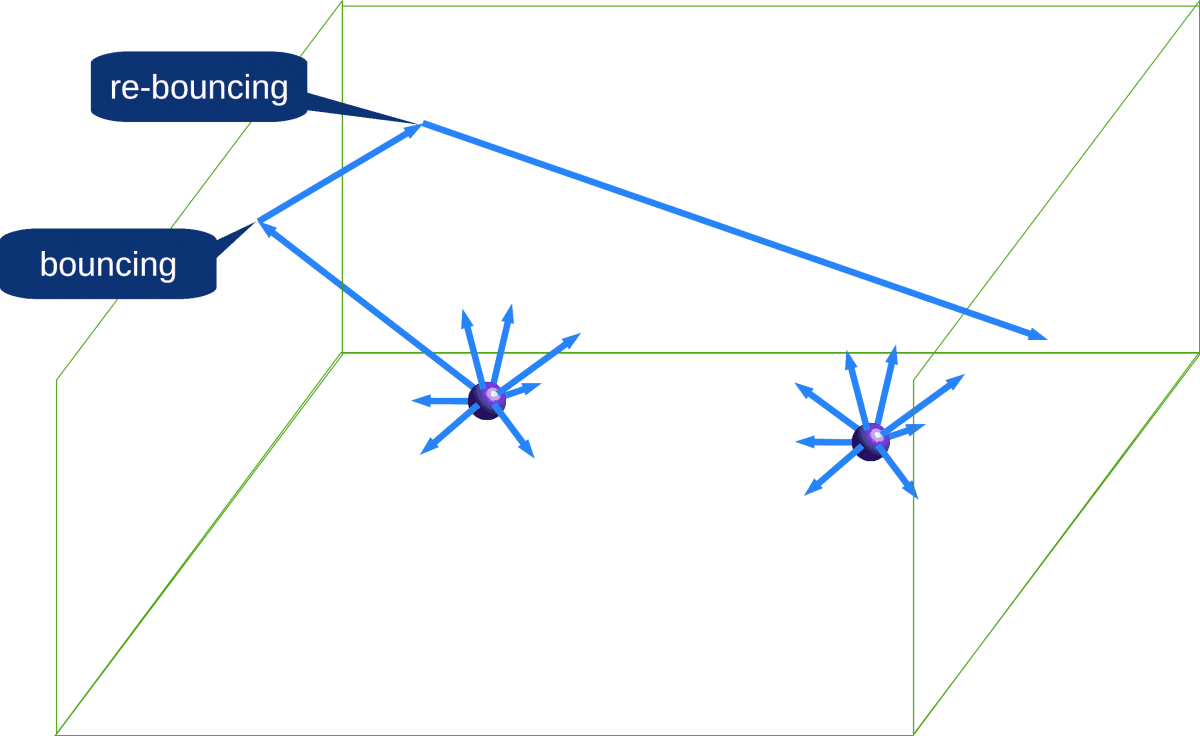
All these direct, bounced and re-bounced rays interfere.
Interference is sum of oscillations in the point of a space (concert hall, listening room).
Oscillations are distributed along rays, as shown above. Lengths of the rays are different. So waves pass way from sound source (musical instrument) to the point with different time delays. And the waves into the point may be as gained as reduced mutually.
Gaining and reducing is not matter in frame of this article. Main issue is correct recording of interference in a point of concert hall and identical reproducing of the interference in a point of a listening room.
Listener ear position may be considered as the point.
It create wave field in concert hall or listening room. The field is various in different points of the room. Because all these rays interfere differently in each point of concert hall. Point here is located in all 3 dimensions.

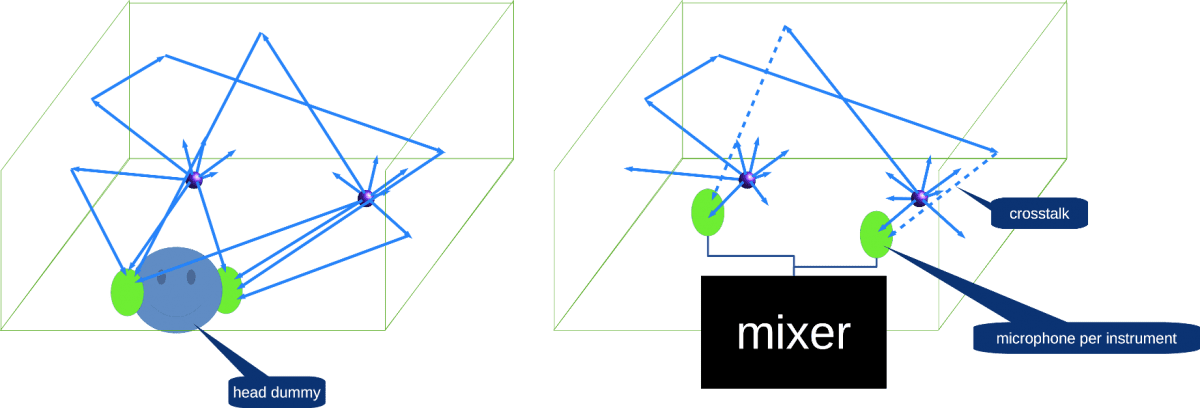
2. Sound of recorded band
Sound of live band captured by microphones.
There are 2 main approaches:
1) 1 microphone per 1 instrument / group instruments / drum unit. Wave field formed artificially, primarily in the mixing, post-production.
2) 2 microphones in a human head model. Sound captured similarly human ears and distributed to record listeners without any processing.
Music recording methods: head dummy and microphone per instrument
Then record is radiated from speakers with some distortions by apparatus. Speakers are omnidirectional sources of acoustic waves too. There are direct acoustic rays, bounced and re-bounced ones also interfere.
Therefore record generate via speakers other sound field, than original live band. Even correctly captured record. Even after absolute elimination of the apparatus distortions.
Therefore, in my opinion, in current level of audio equipment we should discuss quality of sound (acoustic) wave field reproduction, instead traditional sound quality as distortions (harmonic, amplitude distortions and other) of equipment.
Sound field is sound hologram. Like optical hologram (3-D image) is electromagnetic wave field, that our eyes perceive.
Back to top
Implementation issues
Sound hologram is aim of 3-D systems. As rule, these system are multichannel.
There are several issues:
- Proper sound capturing;
- Impact of reflections and re-reflections on speaker precision of record playback;
- Converting of hologram in listening point of concert hall to hologram in position of record-listener ears of listening room.
Capturing

If we want capture sound in one listening position into concert hall, we can use head dummy with microphones in the head dummy's "ears". It is non-trivial thing, as seems at first sight. Because head is complex system of receiving acoustic waves. There is not simply 2 isolated microphones at places of the "ears".
Let's imagine, that we ideally modeled head as soundwave receiver. But there is no ideal model. Because different peoples have different "acoustic wave receivers" (further - "head receiver"). If we can model the head receivers of famous composers, musicians, trained listeners, we can release different editions of one concert (album) :-)
In the first approach, I see "head receiver" as bi-microphone system with two outputs. Using of microphones, with pattern similar to human ear, is desirable. Though it may be not enough for complete simulation of "live listener's ear system.
Microphone pattern is sensitivity of microphone to sound by all direction around in a 3-D space.
Speaker playback issues

Speaker is audio source with complex pattern. I.e. the speaker radiate sound rays with different intensity at different directions. All these rays bounces and re-bounces off many different surfaces into listening room.
Direct acoustic rays from left and right speakers, bounced and re-bounced rays are mixed
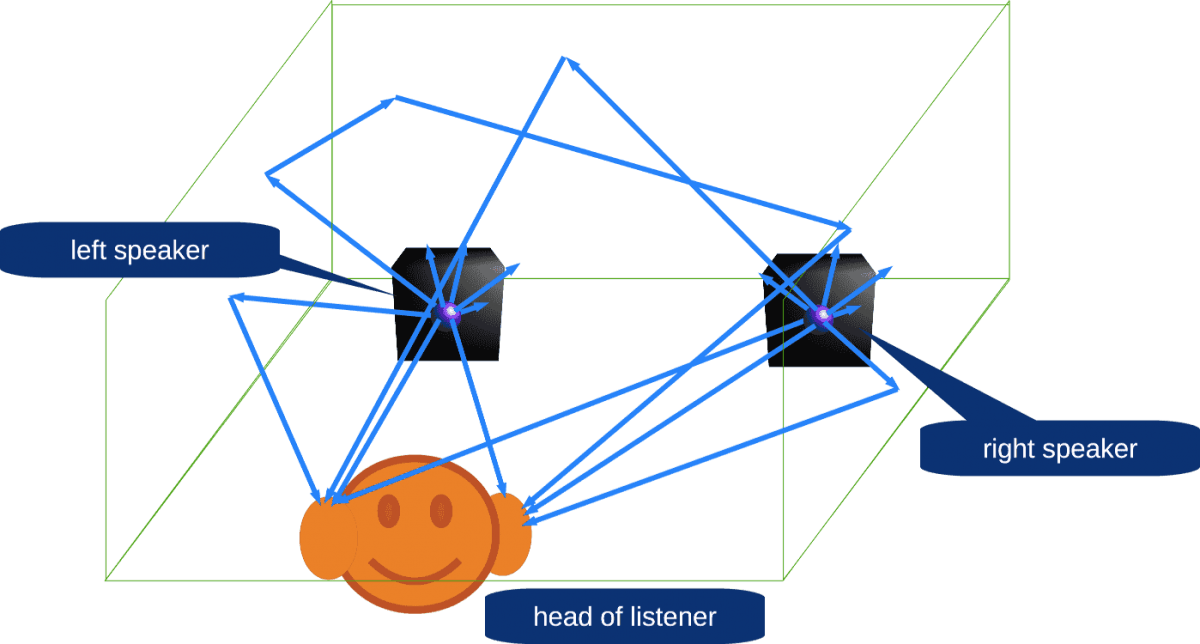
It distort played back sound hologram, even if it is recorded correctly.
Some modern audio systems system use virtual sound source to "draw" it in space of a listening room via speaker array (multichannel system). The array is not hard structure. System can use different kinds of the speaker arrays.
However, it is synthesis of audio object. It is not sound hologram capturing in the concert hall. Though the syntesis is good decision for electronic music and cinemas. I.e. for cases, where sound field may be artificially constructed.
I suppose, that it is reason, why some listeners prefer "simpler" stereo systems.

Headphones playback issues

Into a headphones, driver work in the immediate area of ear, unlike a speaker system.
However, it is not ideal system too. Despite short distance between ear and the driver, headphones is complex acoustic system, that also distort sound hologram. As radiation source there work not only driver, but cap too.
Ear is complex system that receive sound from all directions. I think, here more correctly discuss a head as sound receiver. However, headphones can't reproduce complete acoustic environment of head.
Besides it in concert hall acoustic waves and vibrations impact to human body. However, it more depend on music genre (classic, rock, dance, etc.). The body impact out of headphones abilities too.
I watched picture where speakers was divided by acoustic shield to reduce of crosstalk between left speaker and right ear and contrary. However, it is not way because bouncing issue isn't solved. And sound hologram is distorted there.
Back to top
Wave field synthesis (WFS)
Spatial position of virtual sound source in our brain may be implemented via acoustic wave field synthesis - modeling via digital signal processing.
The synthesis is modeling of spread, adsorbtion, bouncing and re-bouncing of waves in listening room space.
Listening room speakers are used to generate acoustic waves, that are modeled via the wave field synthesis.
Number of speaker is not primal matter.
Before playback room may be measured and/or modeled to correct WFS processing parameters.
After room modeling we can get required speaker number: minimal and recommended.
Too many speakers even may degrade quality of spatial modeling.
Read more: Etienne Corteel. TerenceCaulkins. Clemens Kuhn. A Quick Introduction to Wave Field Synthesis
Back to top
Conclusions
I suppose, that we have potential abilities to obviously improve sound quality in a future audio devices.
It can be implemented via capturing and producing of concert-hall sound field (sound hologram, 3-D sound) in a listening room.
Currently closest way to create sound hologram is capturing of the sound field in a listening point of a concert hall via 2-microphone head dummy and playback it in headphones.
However, it is not cause impact sound to human body, including head fully.
Speaker systems while have acoustic-ray bouncing issue, that significantly distort playback of recorded sound field.
Further sound-field playback device should be easy in use like stereo systems.
- What is Jitter in Audio. Sound Quality Issues >
- 64-bit audio processing. Necessity or redundancy >
- What is Audio Converter >
- How to Choose the Best Audio Converter Software >
- What Is Ringing Audio >
- What is dithering audio? >
- Bit-Depth Audio and Harmonic Distortions >
- Audio as Optics >
- What is optimization audio for DAC >
- Power Conditioner for Audio. It's real advantage? >
Back to top